| Erste Schritte | Hinweise&Tips | Überblick | Referenz | Glossar | Support |
| Technische Referenz: Hauptmenü Statistik: Analyse | |||||
| Analyse des Lernprozesses |
Die folgenden Befehle bietet der Analyse-Dialog (da diese Angaben nur in englischer Sprache vorhanden sind, werden die Stichwörter hier auf englisch so angegeben, wie sie in den Menüs angezeigt werden):
Distributions
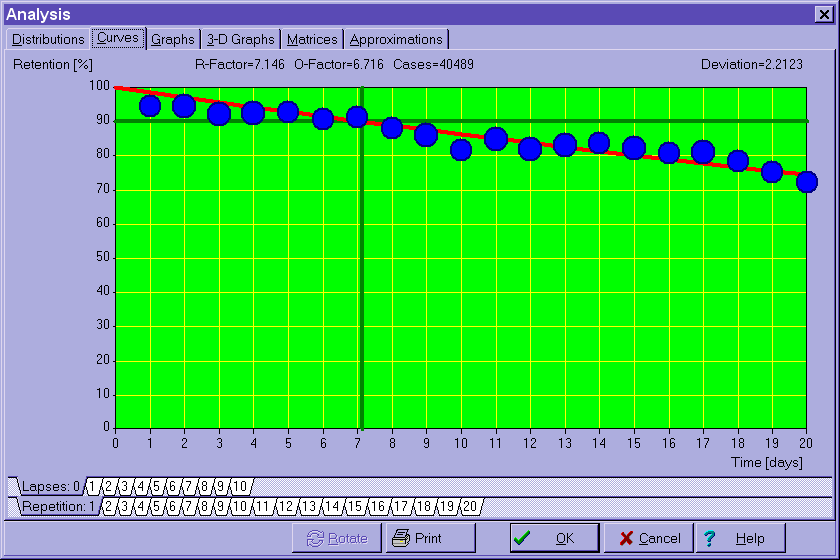
Curves - vierhundert Vergessenskurven werden unabhängig geplottet, um die RF-(=Wiederholungs-Faktor)-Matrix zu berechnen. Diese entsprechen zwanzig Wiederholungszahl-Werten, multipliziert mit zwanzig A-Faktor-Werten (Anmerkung: für die erste Wiederholung sind die Spalten der RF-Matrix nicht durch den A-Faktor, sondern durch die Zahl, wie oft das Item vergessen wurde, indiziert). Wenn Sie eine bestimmte Parameter-Kombination in den Tabulatoren an der Unterseite des Diagramms wählen, können Sie eine Sie interessierende Vergessenskurve auswählen. Die horizontale Achse stellt die Zeit dar, die ausgedrückt wird: (1) als U-Factor, d.h. das Verhältnis von zwei aufeinanderfolgenden Wiederholungsintervallen oder (2) Tage (nur im Fall der ersten Wiederholung). Die vertikale Achse gibt an, wieviele der Elemente behalten wurden (in Prozent):Interval distribution - Verteilung der Wiederholungsintervalle in einer gegebenen WissensdatenbankA-Factor distribution - Verteilung der A-Faktoren in einen gegebenen Wissensdatenbank (Anmerkung: diese Verteilung wird im Algorithmus von SM-8 nicht benutzt, und resultiert nur daraus)
Repetitions distribution - Verteilung der Anzahl der Wiederholungen in einer gegebenen Wissensdatenbank (nur Elemente, die sich im Lernprozeß befinden, werden berücksichtigt, d.h. es gibt keine Wiederholungsintervalle der Länge Null für Elemente, die noch in der Warteschlange stehen).
Lapses distribution - diese Verteilung beschreibt die Häufigkeit, mit der die Elemente der Wissensdatenbank vergessen wurden (nur Elemente, die sich im Lernprozeß befinden, werden berücksichtigt)
Blaue Kreise stellen Wiederholungen dar (je größer der Kreis, desto größer die Zahl der Wiederholungen). Die rote Kurve wurde an die Punkte durch exponentielle Regression angepaßt.
Die horizontale grüne Linie markiert den gewählten Vergessensindex, und die vertikale grüne Linie markiert den Zeitpunkt, in dem sich die approximierte Vergessenskurve mit dem gewählten Vergessensindex schneidet. Dieser Zeitpunkt bestimmt den Wert des relevanten R-Faktors. Die Werte des O-Faktors und des R-Faktors werden an der Oberseite des Diagramms angegeben. Danach wird die Anzahl der Wiederholungen angegeben, die für die Erstellung des Diagramms verwendet wurden.
Beachten Sie, daß es am Anfang des Lernprozesses noch keine Daten zur Zahl der Wiederholungen gibt, die verwendet werden könnten, um die R-Faktoren zu berechnen. Aus diesem Grund werden die Ausgangswerte der RF-Matrix aus dem Gedächtnismodell von Wozniak verwendet, und zwar für den Fall eines unterdurchschnittlichen Studenten (das Modell eines durchschnittlichen Studenten wird nicht benutzt, weil die Konvergenz ausgehend von den Parametern eines schlechteren Studenten nach oben schneller abläuft als in der entgegengesetzten Richtung).
Graphs:
MatricesFI-G graph Das FI-G-Diagramm zeigt die Abhängigkeit des erwarteten Vergessensindex von der bei den Wiederholungen erhaltenen Note. Man könnte sich vorstellen, für die Vergessenskurve die durchschnittliche Note anstelle der Prozentangabe der erinnerten Elemente als vertikale Achse zu benutzen. Wenn Sie diese Note gegen den Vergessensindex auftragen (der 100% minus Anteil der erinnerten Elements ist), erhalten Sie das G-FI-Diagramm.G-AF graph - Die G-AF-Kurve zeigt die Beziehung zwischen der ersten Note eines Items im Lernprozeß zur letzten Schätzung seines A-Faktor-Wertes. Bei jeder Wiederholung wird die alte Schätzung des A-Faktors aus dem Diagramm gelöscht und durch die neue Schätzung ersetzt. Dieses Diagramm wird im SM-8-Algorithmus benutzt, um den ersten Wert des A-Faktors schnell zu schätzen, wenn alles, was wir über ein Element wissen, die erste Note ist, die es bei der ersten Wiederholung erhalten hat.
DF-AF graph: Das DF-AF-Diagramm zeigt die Abnahmekonstante der Polynom-Approximation des R-Faktors entlang der Spalten der RF-Matrix. Die horizontale Achse stellt den A-Faktor dar, während die vertikale Achse den D-Faktor (d.h. Decay factor = Abnahmekonstante) darstellt. Der D-Faktor ist eine Zerfallskonstante der Potenzapproximation der Kurven, die mit dem Approximations-Tabulator in der Dialogbox des Analyse-Fensters aufgerufen werden kann.
First interval graph - die Länge des ersten Intervalls nach der ersten Wiederholung eines Items hängt davon ab, wie oft dieses Item im bisherigen Lernprozeß vergessen worden ist. (Beachten Sie, daß die erste Wiederholung auch die erste Wiederholung sein kann, nachdem das Item vergessen worden ist). Das heißt, auch ein zweimal wiederholtes Item hat die Wiederholungszahl eins, wenn es vergessen worden ist (d.h. die Wiederholungszahl ist nicht drei). Das Diagramm der Längen der ersten Intervalle enthält eine exponentielle Regressionskurve, die die Länge des ersten Intervalls für unterschiedliche Anzahlen von Vergessen approximiert (einschließlich der Kategorie der Vergessenszahl Null für gerade neu erlernte Items).
3-D Graphs - 3-D Diagramme, die die Änderungen von OF-, RF und Cases-Matrizen visualisieren.O-Faktor - Matrix der optimalen Faktoren, indiziert durch die Wiederholungszahl und die A-Faktoren (für die erste Wiederholung wird der A-Faktor durch die Häufigkeit des Vergessens ersetzt).R-Factor matrix - Matrix der Wissens-Retention
Cases matrix - Matrix der Wiederholungen; diese Matrix wird benutzt, um die entsprechenden Einträge der RF-Matrix zu berechnen (doppelklicken Sie einen Eintrag, um die relevante Vergessenskurve anzusehen). Diese Matrix kann manuell bearbeitet werden.
Optimal intervals - Matrix der optimalen Intervalle, abgeleitet aus der OF-Matrix
D-Factor vector - Vektor der D-Faktoren für unterschiedliche A-Faktor-Werte (auch die Wiederholungszahlen werden benutzt, um die D-Faktoren zu berechnen)
Approximations - Zwanzig Potenzapproximationskurven, die die Abnahme des R-Faktors entlang der Spalten der RF-Matrix zeigen. Für jeden A-Faktor verringert sich der Wert des R-Faktors mit der Anzahl der Wiederholungen (zumindest sollte dies theoretisch der Fall sein). Wir verwenden eine Potenz-Regression, um den Grad dieser Abnahme zu veranschaulichen, die gut durch eine Zerfallskonstante beschrieben wird, die wir D-Faktor nennen.Wenn Sie den A-Faktor-Tabulator an der Unterseite des Diagramms wählen, können Sie eine entsprechende R-Faktor-Näherungskurve ansehen. Die horizontale Achse stellt die Wiederholungszahl dar, während die vertikale Achse den R-Faktor darstellt. Der Wert des D-Faktors wird an der Oberseite des Diagramms angegeben. Die blaue, aus Geradensegmenten zusammengesetze Linie, zeigt die R-Faktoren, wie sie aus den Wiederholungs-Daten berechnet wurden. Die rote Kurve zeigt die Fixpunkt-Näherung für den R-Faktor (die Fixpunkt-Näherung wird benutzt, weil für die Wiederholungszahl zwei der R-Faktor gleich dem A-Faktor ist). Die grüne Kurve zeigt die Fixpunkt-Approximation für den R-Faktor aus der OF-Matrix. Dieses Verfahren entspricht einer Substitution des R-Faktors durch den D-Faktor mittels einer linearen DF-AF-Regression.